
Ever thought about how great your personalised Spotify playlists are?
I read an interesting article the other week about how Spotify generate their Discover Weekly playlists based on playlists created by lookalike users, and with the highest level of user-generated playlists among its competitors, Spotify has plenty of data to provide us (their customers) with new music tailored to each of our individual taste profiles.
Surprisingly enough, Spotify also allows developers to tap into their recommendation service through their API. So as a weekend project and as a procrastination method to avoid looming uni assignments, I decided to work on a fun little playlist generator for musictaste. If you’d like to try it out first, head over to musictaste.space and click on the “Create a playlist” button on your dashboard.

Spotify Recommendation API
After spending months on musictaste, I think I’ve fallen in love with the Spotify API. Their documentation is fantastic, and there’s dozens of client libraries available in the open source community to do just about anything you can think of. For this project, I was interested in their recommendations endpoint (see docs here).
Spotify explains that the endpoint works as follows:
Recommendations are generated based on the available information for a given seed entity and matched against similar artists and tracks.
In plain terms, we provide Spotify with some seeds, which can be any combination of tracks, artists or genres (up to five total in combination) and Spotify will return us some tracks that match against these seeds.
This seems rather restrictive, but there’s also some interesting optional parameters that we can pass in to filter the results. These are mainly to do with Spotify’s Audio Features, which let us set limits and thresholds on several attributes. I decided to focus on five:
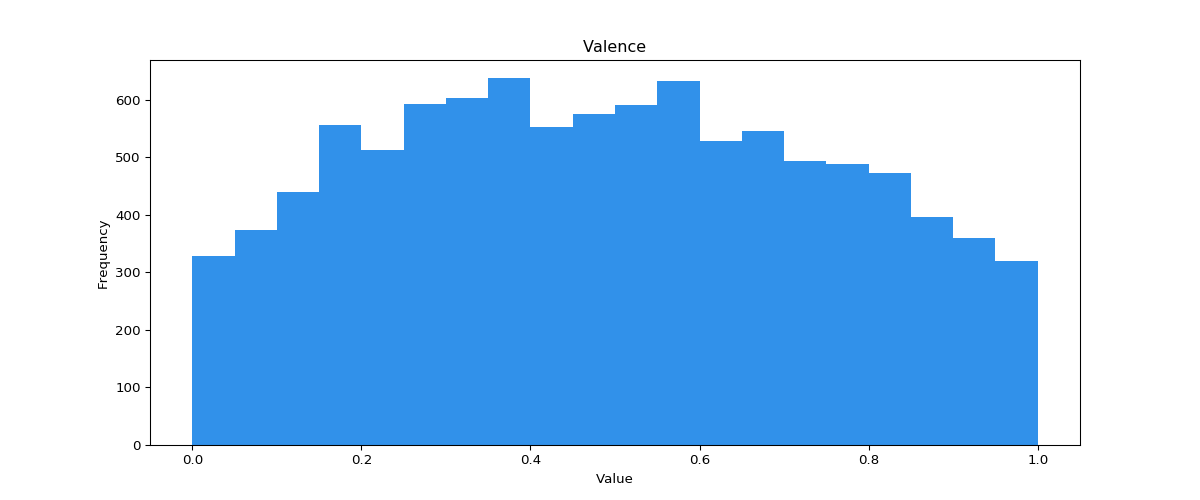
- Valence: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
- Energy: Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy.
- Acousticness: A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic.
- Popularity: The popularity of the track. The value will be between 0 and 100, with 100 being the most popular. The popularity is calculated by algorithm and is based, in the most part, on the total number of plays the track has had and how recent those plays are.
- Danceability: Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.
The Challenge of Option Overload
These tuneable track attributes are cool, but how do we let users decide what filters they want to use? The endpoint allows three sub-options for each attribute:
max_*: For each tunable track attribute, a hard ceiling on the selected track attribute’s value can be provided.min_*: For each tunable track attribute, a hard floor on the selected track attribute’s value can be provided.target_*: For each of the tunable track attributes a target value may be provided. Tracks with the attribute values nearest to the target values will be preferred.
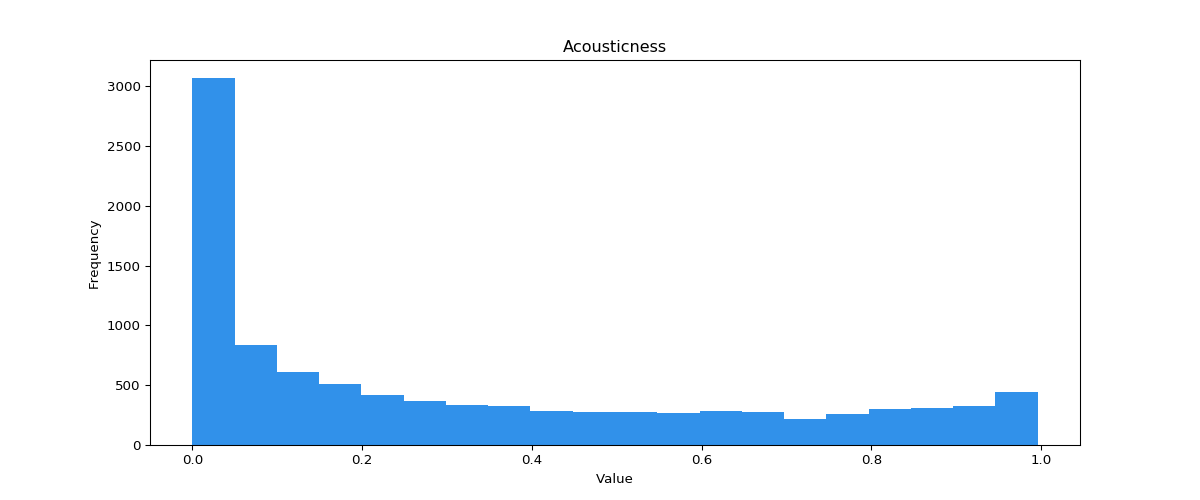
To make matters even more complicated, each feature has its own distribution pattern. For users to use these filters effectively, they also need to keep these distributions in mind. As an example, note the differences in distribution of the features valence and acousticness.
So how do we give users the choices to filter these attributes without overwhelming them with medians, thresholds and distributions?
A Utilitarian Approach
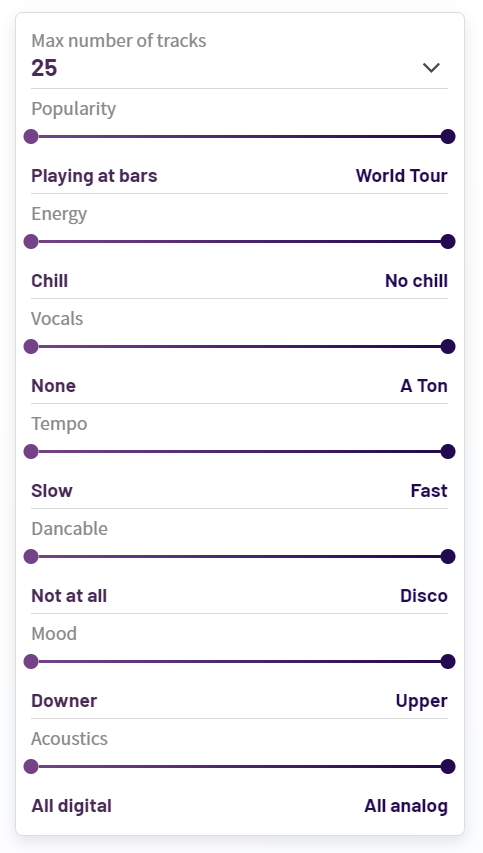
An interesting solution to this problem can be found on Dubolt, a playlist generator webapp that gives users an interface for as many of these filtering options as possible using sliders. I find this approach to be quite elegant, and for many power users they’ll find having this specific level of control extremely useful, but I also find in it some problems:
- Users have to select a range on quite arbitrary and subjective scales. What’s the difference between 25% chill and 50% chill? What does it mean to be in between “Upper” and “Downer” music?
- Users still are unaware of the underlying distribution on scales. An issue arises when you select a range for some attribute which is significantly far from the mean. For example, choosing a range of 0.6 – 0.9 along acousticness would exclude over 80% of tracks without the user realising.
- Many options lead to information overload. The average user likely doesn’t care for finely tuning all of these options for a playlist. This fine level of control allows for refined and predictable outcomes, but is that what people want? The beauty of the black box often makes the experience seem more magical than it actually is.
Emojis To The Rescue 😁
That’s when I had the idea to use emojis to abstract away the refinement of these track attributes. It creates a novel way to interact with the interface, and makes the experience more enjoyable to the casual user.
Under the hood, this allows us to:
- Abstract away the unique distributions of features and work outwards from the means. If selects that they want a more acoustic track, we begin at the mean of the acousticness feature (around 0.1) and step up by some degree of freedom.
- Abstract the min/max thresholds through inference. If a user’s options state that they want a super danceable track, we can infer that we should set a minimum cutoff at a sensible level for this user. In the same way, if they want very sad songs, we can infer that we should have a maximum cutoff on valence to avoid happy songs creeping in.
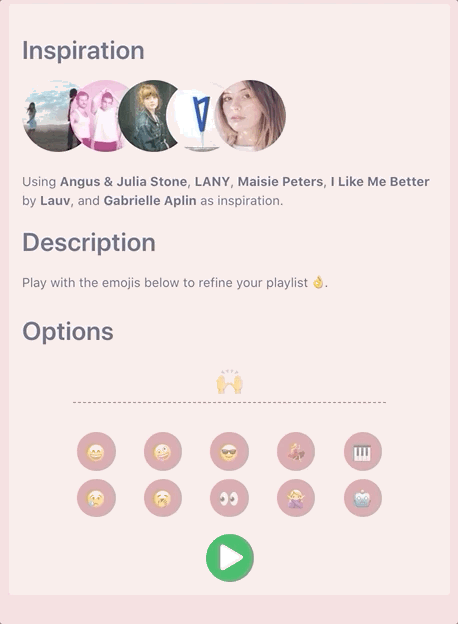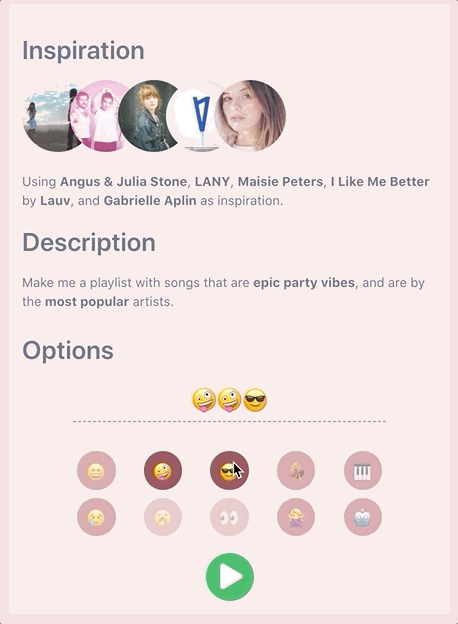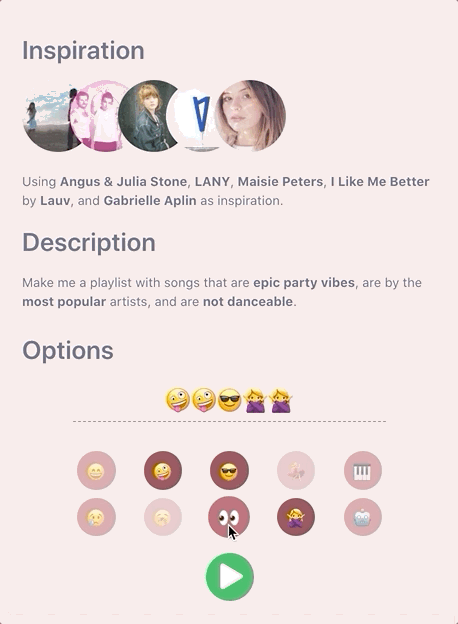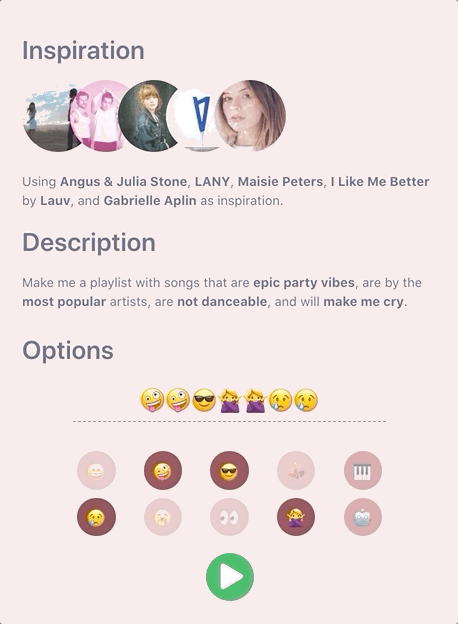
Setting Targets and Chaining Emojis 🔗
To help simplify the problem of using emojis to control filters, let’s initially only modify the target_* values in the recommendation options object for each feature. When a user enters a sad emoji, say 😢, we should set the corresponding target attribute (in this case target_valence) to a low number. That’s easy enough, but what if we want to provide a little more control? One sad emoji might mean the user only wants some sad songs, but not a depressive breakup playlist.
We can handle this by setting up some means, boundary conditions and a number of multipliers for both negative and positive emojis affecting each feature. Check out this simplified setup:
/**
* Base information for each feature.
*/
const baseFeatures = {
acousticness: { mean: 0.1, max: 0.9, min: 0 },
danceability: { mean: 0.7, max: 0.9, min: 0.2 },
energy: { mean: 0.8, max: 1, min: 0 },
popularity: { mean: 0.5, max: 0.9, min: 0.1 },
valence: { mean: 0.5, max: 1, min: 0 },
}
/**
* Maps an array of emojis to a corresponding feature.
*/
const emojiToTargetMap: Array<[
string[],
{ feature: string; multiplier: number }
]> = [
[['🎻', '🎹', ...], { feature: 'acousticness', multiplier: 1.3 }],
[['🔌', '🤖', ...], { feature: 'acousticness', multiplier: 0.6 }],
[['💃', '🕺', ...], { feature: 'danceability', multiplier: 1.3 }],
[['🥔', '🙅♀️', ...], { feature: 'danceability', multiplier: 0.8 }],
[['😴', '🥱', ...], { feature: 'energy', multiplier: 0.7 }],
[['🏃♂️', '🏃♀️', ...], { feature: 'energy', multiplier: 1.3 }],
[['😀', '🥰', ...], { feature: 'valence', multiplier: 1.3 }],
[['😢', '😭', ...], { feature: 'valence', multiplier: 0.7 }],
[['😎', '🤩', ...], { feature: 'popularity', multiplier: 1.3 }],
[['🕵️♂️', '👀', ...], { feature: 'popularity', multiplier: 0.7 }],
]
/**
* A function to look up an emoji in the target map.
*/
const lookUpEmoji = (char: string) => {
const data = emojiToTargetMap.reduce(
(prev, curr) => (curr[0].includes(char) ? curr[1] : prev),
null
)
return data
}
So with this new logic, when a user adds an emoji to the options string, we want to:
- Look up the emoji for its corresponding feature.
- If a target value for that feature has previously been set, apply the multiplier to the existing value and make sure its within the min and max thresholds.
- If a target value for that feature has not yet been set, apply the multiplier to the feature mean.
Tying It Into A Reducer
musictaste is built with React, so I incorporated this function into the reducer of the playlist creation page using the useReducer hook. Tying it all together quite simply, we get the code:
/**
* Example action.
*/
const action = {
type: 'target',
payload: { character: '👀' },
}
/**
* Reducer case for a new emoji.
*/
switch (action.type) {
case 'target':
// get emoji from lookup
const lookupData = lookUpEmoji(action.payload.character)
if (lookupData) {
// get base feature information
const baseFeature = baseFeatures[lookupData.feature]
return {
...state,
[`target_${lookupData.feature}`]: state[`target_${lookupData.feature}`]
? // if target already set, apply multiplier on existing value
Math.max( // ensure its in range
baseFeature.min,
Math.min(
state[`target_${lookupData.feature}`] * lookupData.multiplier,
baseFeature.max
)
)
: // else use feature mean
targetBase[lookupData.feature] * lookupData.multiplier,
}
}
return state
}Our reducer now examines the emojis in the input and mutates the state object which mimics the recommendation options object to be passed to the Spotify API.
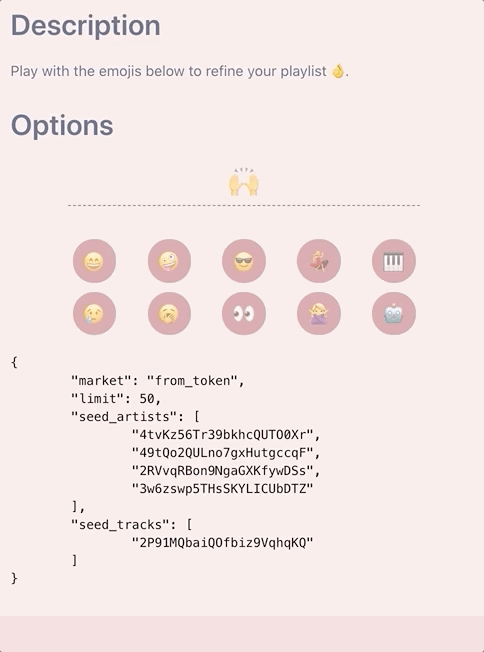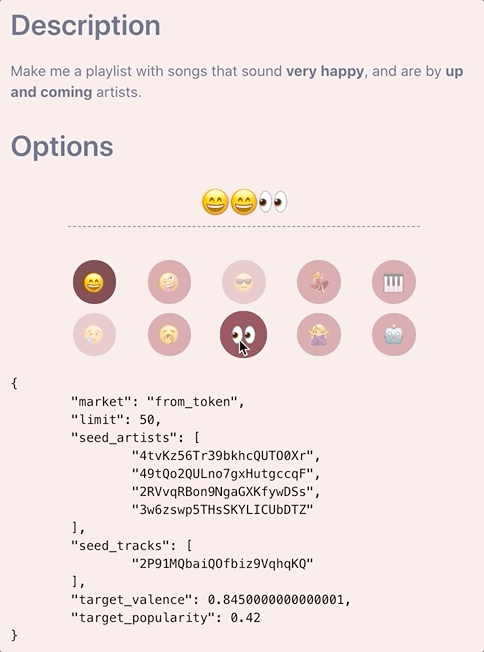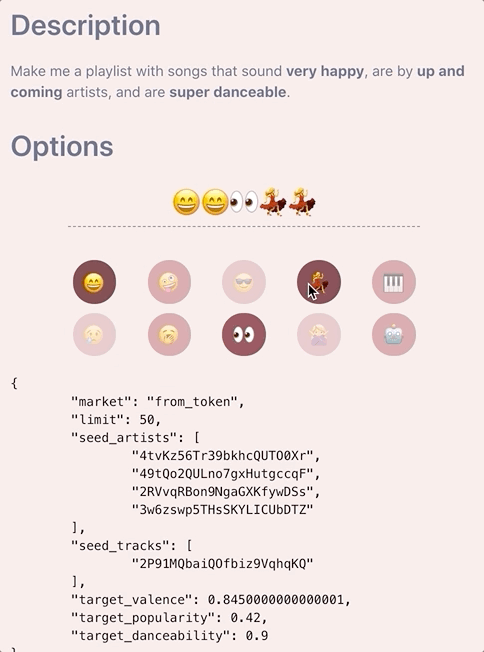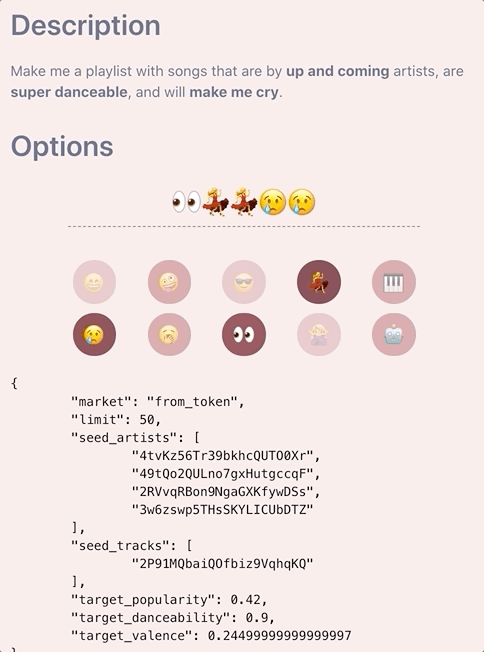
The Final Piece
Once we have the target values for each feature, we can now decide whether we want to apply the min/max thresholds for any of these attributes. This is done just prior to calling the Spotify API along with a final pass of the tracks and artists to extract genres to pass in as additional seeds if the user specified less than five (testing found that passing in the maximum five seeds allows for better variety of response tracks but this post is long enough as is to go into how to best determine how to fill the missing gaps). As mentioned earlier, determining whether to set a min_* or max_* attribute is quite straightforward. The basic thought process is that if a user requests super sad songs, our target_valence is likely to be very low (< 0.2). We don’t want tracks with high valence ruining the vibes of our playlist, so we can set a max_valence: 0.5, choosing 0.5 because the distribution of valence is centred around this value.
And that’s it! Thanks for joining me on this little weekend experiment. Have a try of the playlist generator on musictaste and see what the magical black box suggests to you — maybe you’ll find inspiration for your next playlist masterpiece.